TCP Performance Options

In order to understand application performance across the network, we first have to understand the basic mechanisms. In this case that foundation is built on TCP, and, more specifically, the built-in TCP Performance Options. There are many things that can be done in an application to improve performance. There are also several options from a network perspective, and more still in the operating systems. However, these all rely on the underlying protocol.
The Warm Up
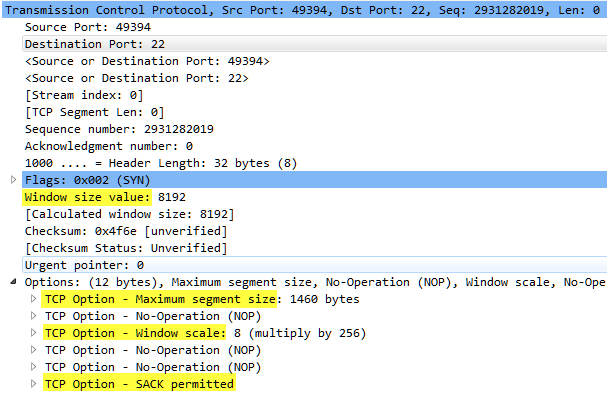
This blog can serve as a warm up to understanding TCP performance. But, it is still a high-level overview and based on my knowledge and experience. So, for other perspectives I have included some other blog links below in the “Other References” section. These are blogs from some experts in the field and I highly recommend reviewing their content and subscribing to them as well. Nothing beats going straight to the source; however, so I’ve also included some of the RFCs pertaining to TCP performance in the “RFC References” sections. The TCP options we concern ourselves with are highlighted in this image:
By now, the test application is open and ready and Wireshark is waiting to start. Once you’re familiar with TCP and its options and patterns, you’re ready to put on your favorite pair of running shoes and head to the main event.
Stepping up to the Line
The very nature of TCP is to provide a measured and controlled exchange of data between two devices with data loss recovery options. If this were an actual race, TCP would look more like a race at a birthday party where participants are trying to fill a bucket of water by carrying spoonfuls across the yard in a relay fashion. UDP would actually look more like a 5k with everyone darting off at random hoping to make it to the end. Before packets hit the wire, though, it’s important to remember where the capture driver retrieves packets. It grabs them before the NIC, so other factors such as offloading (TSO and RSO) can skew the variables in Wireshark. Please be aware of this when analyzing the data. The highlighted options in the image above provide the means for TCP to measure and control the performance of a stream of data. Here we will examine these options.
MSS
In the very first packet of a conversation (the SYN packet), the maximum segment size (MSS) is negotiated. This value informs each device of the largest payload they can send per packet. If this were a train, it would represent the amount of material each car could hold. This number is constrained by more headers at lower layers such as when communicating over a VPN or through tunnels. It can be increased from the standard when jumbo frames are allowed, such as within a data center or modern LAN. There are various reasons for a device or application choosing whether to fill the packets to the brim or not.
Window Size
The window size refers to the amount of bytes that can be sent, or more accurately, received, before an acknowledgment is required. This value will change per packet as the receiver updates the sender with how much available space is left. This can be constrained by unacknowledged data, or other receiver-side problems such as memory or processor issues or any other myriad of problems.
Window Scale
Window scaling was introduced in order to extend the window size. The Window Size field is 16-bits long with a maximum value of 65.535 bytes. Window scaling extends it by bit-shifting the field in the TCP header up to another 16 bits (though the max is actually 14). This is most useful in the case of Long Fat Networks (LFN, aka elephants) where bandwidth is good, but latency is high.
SACK
Selective Acknowledgement is actually used to aid in packet loss. It allows for the receiver to acknowledge incoming packets while still awaiting for the arrival of a missed packet. I’ve included it in this post, because reducing the number of retransmitted packets does improve performance.
Off to the Races
Once the packet hits the wire, the race begins! Everything begins with the TCP handshake. Not just TCP options either. These are the first packets of a TCP thread, so the underlying network begins its tasks as well. This is where the route and timing are determined along with learning how congested a link is or if there is any packet loss. Taking that first step even sets expectations. In this example, the 3 handshake packets provide the following information:
Latency is 100 ms
MSS is 1460 bytes
Window Scaling Factor is 8 (multiply by 256)
SACK is permitted
The other network factor in this case is the link speed of 300 Mbps.
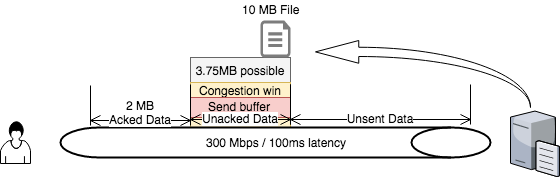
TCP performance cannot be measured, let alone have expectations set, without reviewing the bandwidth-delay product (BDP). The BDP is simply the bandwidth multiplied by the delay (latency) of a link. Its purpose is to determine the maximum performance of a connection. Using the data from above, this is the BDP.
BDP = 300 Mb / 8 bytes per MB * 100ms (.1) = 3.75 MB of unacknowledged data allowed to be in transit on the network (i.e. in flight).
OK, so while the formula is simple from a math standpoint, it still requires a bit of explanation. The division by 8 allows for the conversion from bits to bytes (or MB) to keep everything comparable. The resulting number is actually the amount of data that is allowed to be on the wire before reaching the receiver and before the sender sends more (unacknowledged data). The options mentioned above and this formula prove that while application performance is affected by bandwidth and latency, it is not determined by it. Sure, bandwidth and latency help the average person know if they have a decent connection, but just knowing you have a good pair of shoes and a fitbit doesn’t make you a good runner. There is so much more to it.
To understand all of this, think of the packets as a train. Using the provided numbers, the application can send 3.75MB of data at a time in packets of 1460 bytes each with a round trip time of 100ms. In order to send more packets, the previous ones need to be acknowledged. This means roughly 2500 packets could be in flight. However, this is when the window size comes into the picture. Using the traditional maximum windows size and dividing that by the BDP the resulting number is the percentage of bandwidth utilization possible. In this case, the result isn’t good due to it being a long, fat network (LFN).
65,535/3,750,000 = 1.7% possible utilization
So, out of a 300Mbps pipe, only 5Mbps is even possible? No. This is why the windows scaling factor is so important. It allows applications to achieve a higher window than 65,535 bytes.
65,535 * 256 (scaling factor in this case) = 16,776,960. 16,776,960 / 3,750,000 = 4.4739 (447%).
Now the application can flood the link. While this sounds good in theory, many users would be left complaining that the network was slow and unusable. Receivers will generally set their windows to what they can handle. But, senders also have to respect congestion windows and flow control. These others measures bring the performance back to a happy middle ground where optimal bandwidth consumption is achieved and other applications can continue performing properly. Unfortunately, the sender’s congestion window and send buffer cannot be determined by the network. The only way to view these metrics is to get them from the server itself.
The Finish Line
After sweating through performance calculations, reading RFCs about TCP, and probably learning more than you ever wanted to about a single protocol (I know I have), you have nearly reached the finish line; and just as your file transfer is completing after its journey across the “elephant” (LFN). But even though this is the end of one race, the next is just beginning. There is so much more to learn about TCP, and even more about application performance. I mean what happens when you add the different versions of SMB on top of TCP!? I will end this post with a diagram that should help bring this all together. Part 2 will focus on viewing TCP performance in Wireshark.
RFC References:
- RFC2001 – TCP Algorithms
- RFC2581 – TCP Algorithms Update
- RFC7323 – TCP Extensions for High Performance
Other References:
- https://www.dynatrace.com/blog/understanding-application-performance-on-the-network-tcp-slow-start/
- https://technet.microsoft.com/en-us/library/2007.01.cableguy.aspx
- http://packetlife.net/blog/2010/aug/4/tcp-windows-and-window-scaling/
- http://packetbomb.com/understanding-throughput-and-tcp-windows/
- http://packetbomb.com/how-to-troubleshoot-throughput-and-tcp-windows/